
In the realm of deep learning, acquiring and training models on extensive datasets is a foundational requirement for achieving effective outcomes. However, a common and detrimental issue that emerges during this process is label noise, which can significantly hinder classification accuracy. Labels are pivotal for guiding the training process, and when these labels are erroneous or inconsistent, the overall performance of models on test datasets can fall short of expectations. This necessitates innovative solutions that can effectively mitigate the adverse effects of such noise.
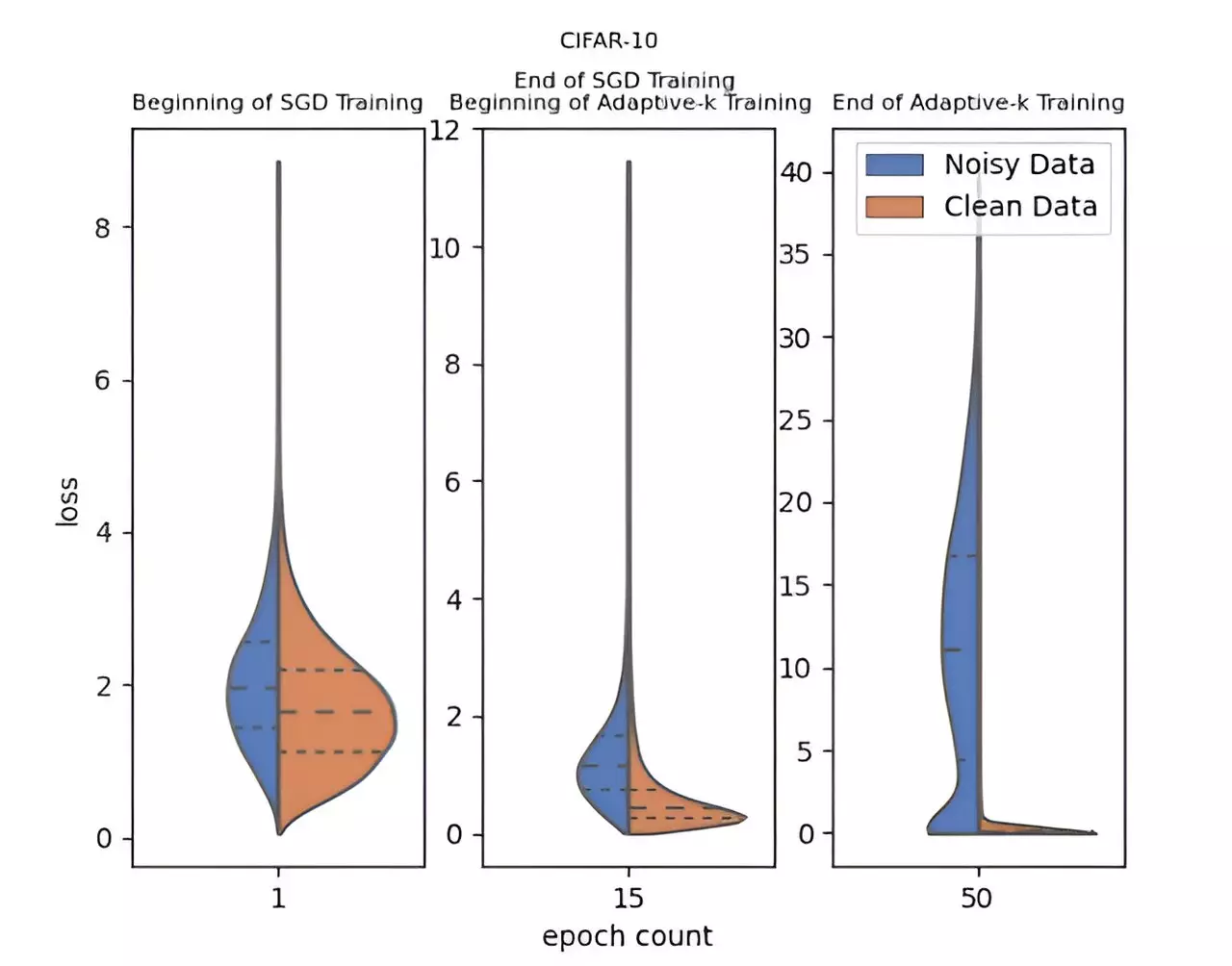
To tackle the challenges posed by label noise, a groundbreaking method known as Adaptive-k has been introduced by a team of researchers from Turkey’s Yildiz Technical University, including Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali. Published in the esteemed journal Frontiers of Computer Science, Adaptive-k differentiates itself by actively and adaptively determining how many samples from each mini-batch will be utilized for updating model parameters. This thoughtful approach allows for an improved ability to discern and separate noisy samples from clean ones, ultimately leading to more successful training outcomes even when confronted with noisy datasets.
What sets Adaptive-k apart from other methods is its simplicity and efficiency. This innovative technique does not demand prior knowledge about the dataset’s noise ratio, nor does it require the addition of supplementary training or substantial increases in processing time. This usability aspect makes Adaptive-k particularly appealing for practitioners who may not possess extensive resources or prior experience in handling label noise. By performing closely to the Oracle method—where all noisy labels are removed—Adaptive-k presents a viable pathway to achieving remarkable results in less-than-ideal conditions.
The research team conducted exhaustive comparisons of the Adaptive-k method against other established algorithms such as Vanilla, MKL, Vanilla-MKL, and Trimloss. Employing three distinct image datasets and four text datasets in their experiments, the researchers demonstrated a consistent superiority of Adaptive-k in environments characterized by label noise. Furthermore, this method showcases its versatility through compatibility with various optimization techniques, including Stochastic Gradient Descent (SGD), SGD with Momentum (SGDM), and the Adam optimizer.
The implications of the Adaptive-k method are far-reaching, providing a robust framework for the training of deep learning models in the face of label noise challenges. With significant contributions to algorithmic simplicity and performance metrics, the research team is focused on further refining the Adaptive-k approach. Future efforts will aim to deepen the exploration of its applications across different domains and enhance its efficacy even further. As the field of deep learning continues to evolve, the Adaptive-k method stands to play a pivotal role in shaping robust training paradigms for noise-prone datasets.
As deep learning applications proliferate, addressing inherent challenges like label noise becomes critical. The Adaptive-k method represents a strategic advancement in overcoming these hurdles, promising a revolution in how deep learning models are trained and evaluated.